EM(期望最大化)
EM算法是包含隐藏变量的极大似然估计算法。
它涉及到迭代交替求解对数似然函数的期望和最大化似然的参数。
常见的应用包括拟合混合模型、包含潜在参数的贝叶斯网络和隐马尔可夫模型。
1.Jensen不等式
定理:
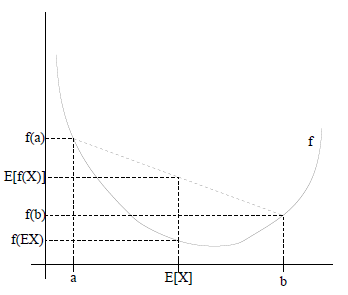
如果是凸函数,是随机变量,那么
如果是严格凸的,那么成立,当且仅当的概率为100%,也就是说X是一个常量。
这里把简写成。
如下图所示,实线是一个凸函数,有0.5概率是a,0.5的概率是b(就像抛硬币一样)。的期望就是a和b的中值。
Jensen不等式应用于凹函数时,不等号方向相反,
2.EM算法
给定一个包含个样本的训练集{ },样本间相互独立,我们想知道每个样本隐含的类别z,能使得最大的,其中的似然函数如下:
第一步是对极大似然取对数,将求积变成求和;第二步是对每个样本的每种类别求联合分布概率和。但是直接求解是很困难的,因为这里有一个潜在随机变量。一旦确定了,求解就容易了。
在这种情况下,EM算法给出了一个有效的求解极大似然估计的方法。直接最大化很困难,EM的策略是,反复地构造的下界(E-step),然后最优化这个下界(M-step)。
对于每一个样例,用表示该样例隐含变量的某种分布,满足的条件是,,。(如果z是连续性的,那么是概率密度函数,需要将求和符号换做积分符号)。比如,要将班上学生聚类,假设隐藏变量是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
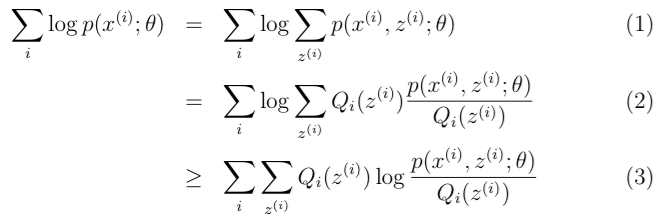
(2)到(3)运用了Jensen不等式,是凹函数(,在的定义域里永远为负数)